파이썬으로 다양한 프로그램을 만들다가 마침 네이버 인기검색어가 없어져서, 뭔가 인기 검색어를 긁어 올 수 있는 방법이 있을까 생각하다가 아직까지 인기검색어 시스템을 유지하고 있는 구글, 줌, 키자드에서 인기검색어를 긁어오는 프로그램을 한번 만들어 봤습니다.
구조자체는 굉장히 단순합니다. beautifulsoup를 통해서 사이트의 텍스트를 긁어 오는 방식입니다. 따로 로그인도 필요 없기 때문에 크롤링을 이용하기만 하면 가능합니다.
import time
import re
import requests
from bs4 import BeautifulSoup
def keyzard():
URL='https://keyzard.org/realtimekeyword'
html = requests.get(URL)
soup = bs(html.text, 'html.parser')
req=soup.select('td.ellipsis100')
for keyzard in req:
print(keyzard.text)
def google():
URL='https://trends.google.com/trends/trendingsearches/daily/rss?geo=KR'
html = requests.get(URL)
soup = bs(html.text, 'html.parser')
req=soup.select('item > title')
for i,google in zip(range(21),req):
print(google.text)
def zum():
URL='https://issue.zum.com/'
html = requests.get(URL)
soup = bs(html.text, 'html.parser')
req=soup.select('div.cont > span.word')
for i,zum in zip(range(10),req):
print(zum.text)
keyzard()
google()
zum()함수별로 짜놓고
함수를 호출해 주시면 됩니다.
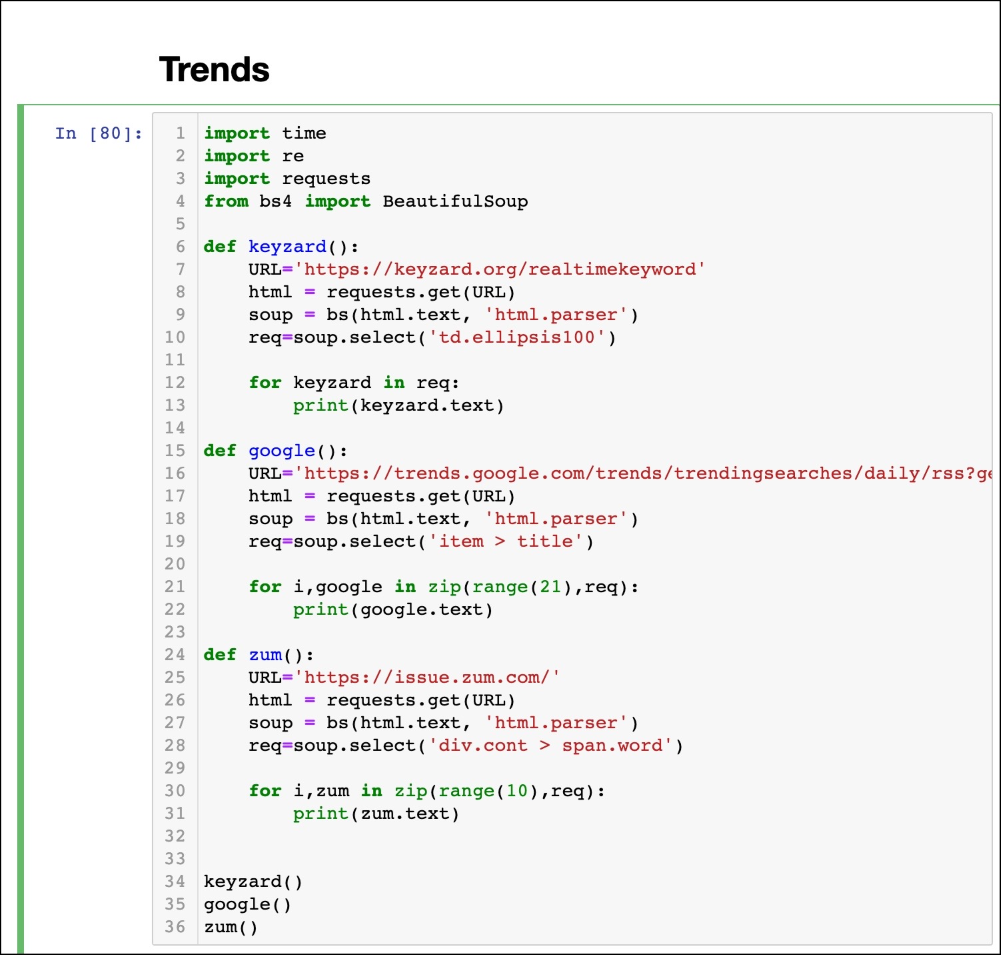
36줄 정도, 공백 없애면 30줄 안으로 3가지 사이트를 긁어 올 수 있습니다.

최근 인기 많은 항목들을 다 긁어와 주게 됩니다. 이걸 이용해서 블로그 주제를 뽑느다던지 여러 방면으로 사용할 수 있을 것 같습니다.